Install pssh, to batch config spark slaves
1 | wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.coms/parallel-ssh/pssh-2.3.1.tar.gz |
使用参见:
System config in master
/work/hosts
1 | root@192.168.4.210 |
/etc/hosts
1 | 127.0.0.1 localhost |
/etc/environment
1 | LANGUAGE="zh_CN:zh:en_US:en" |
/work/spark/conf/spark-env.sh,update ens3 to your network interface
1 | export SPARK_LOCAL_IP=$(ifconfig ens3 | grep "inet addr:" | awk '{print $2}' | cut -c 6-) |
update_hostname.sh, update default hostname ubuntu to n{machine ip last number}
1 | !/usr/bin/env bash |
Init master and slaves in master
1 | pssh -h hosts "apt update" |
Hadoop config in master
此处引入hadoop是为了slaves从hadoop拉去资源启动app;
当然,也可以复制jar到各slaves相同的路径启动;
后面发现,每次重启app,spark都会从hadoop全量拉取一遍资源到spark/work目录。
core-site.xml
1 |
|
hdfs-site.xml
1 |
|
init hadoop
1 | create hadoop user in master |
copy_app_resouces_to_hadoop.sh, run as hadoop user
1 | !/bin/bash |
Exception solutions
fix spark WorkWebUI hostname(logs) 指向master机器hostname
看源码,在
spark-env.sh中指定SPARK_LOCAL_HOSTNAME并没起作用,解决方案:设置
SPARK_PUBLIC_DNS参数后,worker webui中的跳转链接正常了。SPARK_PUBLIC_DNS→publicHostName我也是服了,如下图,原先
stdout的链接的的主机为n0,n0为master所在的机器: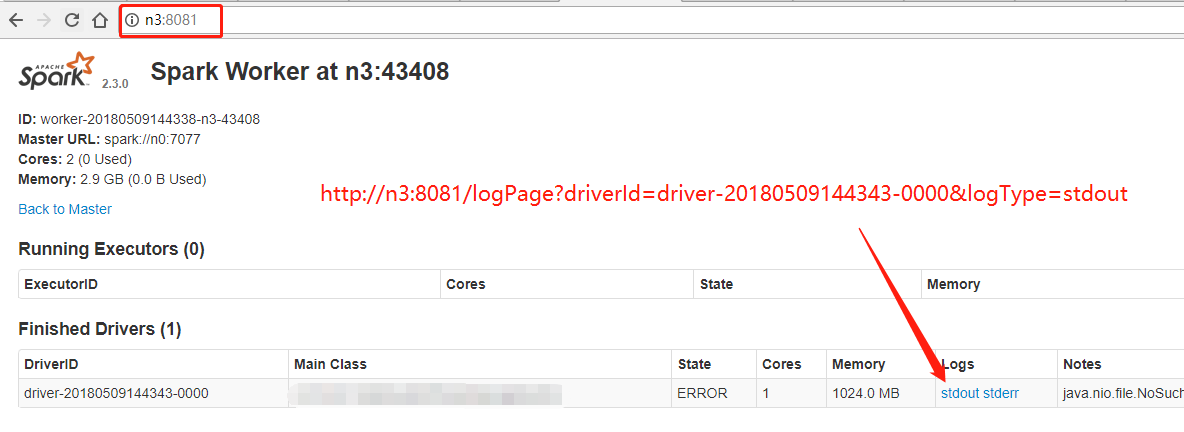
源码参考
core/src/main/scala/org/apache/spark/ui/WebUI.scala
1
2
3
4
5protected val publicHostName = Option(conf.getenv("SPARK_PUBLIC_DNS")).getOrElse(
conf.get(DRIVER_HOST_ADDRESS))
/** Return the url of web interface. Only valid after bind(). */
def webUrl: String = s"http://$publicHostName:$boundPort"core/src/main/scala/org/apache/spark/util/Utils.scala
1
2
3
4
5
6
7
8
9private lazy val localIpAddress: InetAddress = findLocalInetAddress()
private var customHostname: Option[String] = sys.env.get("SPARK_LOCAL_HOSTNAME")
/**
* Get the local machine's URI.
*/
def localHostNameForURI(): String = {
customHostname.getOrElse(InetAddresses.toUriString(localIpAddress))
}
spark ConsumerRecord NotSerializableException bug
1
2
3
4
5
6
7
8
9
10
11
12java.io.NotSerializableException: org.apache.kafka.clients.consumer.ConsumerRecord
Serialization stack:
- object not serializable (class: org.apache.kafka.clients.consumer.ConsumerRecord, value: ConsumerRecord(topic = hi2, partition = 4, offset = 385, CreateTime = 1526369397516, checksum = 2122851237, serialized key size = -1, serialized value size = 45, key = null, value = {"date":1526369397516,"message":"0hh2KcCH4j"}))
- element of array (index: 0)
- array (class [Lorg.apache.kafka.clients.consumer.ConsumerRecord;, size 125)
at org.apache.spark.serializer.SerializationDebugger$.improveException(SerializationDebugger.scala:40)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:46)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:100)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:393)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)解决方案
set SparkConf
1
2sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
sparkConf.set("spark.kryo.registrator", "me.codz.registrator.CunstomRegistrator");create CunstomRegistrator
1
2
3
4
5
6
7
8
9
10
11
12
13package me.codz.registrator;
import com.esotericsoftware.kryo.Kryo;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.spark.serializer.KryoRegistrator;
public class CunstomRegistrator implements KryoRegistrator {
public void registerClasses(Kryo kryo) {
kryo.register(ConsumerRecord.class);
}
}spark TaskContext.get() cause NullPointerException
1
2
3
4
5
6
7
8
9
10
11
12
13stream.foreachRDD((VoidFunction2<JavaRDD<ConsumerRecord<String, String>>, Time>) (v1, v2) -> {
OffsetRange[] offsetRanges = ((HasOffsetRanges) v1.rdd()).offsetRanges();
List<ConsumerRecord<String, String>> consumerRecordList = CollectionTools.emptyWrapper(v1.collect());
consumerRecordList.forEach(consumerRecord -> {
TaskContext taskContext = TaskContext.get();
int partitionId = taskContext.partitionId();
OffsetRange o = offsetRanges[partitionId];
//...
});
});解决方案
usingforeachPartition1
2
3
4
5
6
7
8
9
10
11
12
13
14v1.foreachPartition(consumerRecordIterator -> {
while (consumerRecordIterator.hasNext()) {
ConsumerRecord<String, String> consumerRecord = consumerRecordIterator.next();
//...
}
TaskContext taskContext = TaskContext.get();
int partitionId = taskContext.partitionId();
OffsetRange offsetRange = offsetRanges[partitionId];
//...
});
});Spark app connect kafka server by ip suspend
1
22018-06-07 18:40:16 [ForkJoinPool-1-worker-5] INFO :: [Consumer clientId=consumer-1, groupId=node-quality-streaming] Discovered group coordinator lau.cc:9092 (id: 2147483647 rack: null)
2018-06-07 18:40:18 [ForkJoinPool-1-worker-5] INFO :: [Consumer clientId=consumer-1, groupId=node-quality-streaming] Group coordinator lau.cc:9092 (id: 2147483647 rack: null) is unavailable or invalid, will attempt rediscovery解决方案
vim kafka/config/server.properties
1
2#add follow line
advertised.host.name=192.168.3.20kafka
advertised.host.nameDEPRECATED since 0.10.x, 0100 brokerconfigs1
DEPRECATED: only used when `advertised.listeners` or `listeners` are not set. Use `advertised.listeners` instead. Hostname to publish to ZooKeeper for clients to use. In IaaS environments, this may need to be different from the interface to which the broker binds. If this is not set, it will use the value for `host.name` if configured. Otherwise it will use the value returned from java.net.InetAddress.getCanonicalHostName().
so follow config can also take effect
1
2listeners=PLAINTEXT://192.168.3.20:9092
advertised.listeners=PLAINTEXT://192.168.3.20:9092mark
1
2
3java.lang.OutOfMemoryError: unable to create new native thread
Offsets out of range with no configured reset policy for partitions
Zookeeper cluster init
1 | tar -zxvf zookeeper-3.4.12.tar.gz -C /work |
vim conf/zoo.cfg
1 | tickTime=2000 |
bin/init_myid.sh, update ens3 to your network interface
1 | !/bin/bash |
init cluster myid
1 | pssh -h /work/hosts "/work/zookeeper/bin/init_myid.sh" |
start zookeeper cluster
1 | pssh -h /work/hhosts -o out "/work/zookeeper/bin/zkServer.sh start" |