实现图形验证码大致分为5步上来完成:
- 建立图形缓冲区;
- 在图形缓冲区用随机颜色填充背景。
- 在图形缓冲区上输出验证码。
- 将验证码保存在HttpSession对象中。
- 向客户端输出图形验证码。
通过 ValidationCode 类来实现验证码功能,该类也是Servlet类,在客户端只要像访问普通Servlet一样访问ValidationCode类即可。
1 | package com.cnblogs.jbelial.Validation; |

实现图形验证码大致分为5步上来完成:
通过 ValidationCode 类来实现验证码功能,该类也是Servlet类,在客户端只要像访问普通Servlet一样访问ValidationCode类即可。
1 | package com.cnblogs.jbelial.Validation; |
在tomcat目录server.xml里面加入
1 | <valve classname="org.apache.catalina.valves.AccessLogValve" directory="logs" prefix="localhost_access_log." suffix=".txt" pattern="common" resolvehosts="false"></valve> |
两种请求在请求的Header不同,Ajax 异步请求比传统的同步请求多了一个头参数
传统同步请求参数
1 | accept text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8 |
Ajax 异步请求方式
1 | accept / |
可以看到 Ajax 请求多了个 x-requested-with ,可以利用它,request.getHeader("x-requested-with"); 为 null,则为传统同步请求,为 XMLHttpRequest,则为 Ajax 异步请求。
下面是Struts拦截器示例代码:
1 |
|
开发网站的时候,常常需要自己配置Linux服务器。
本文记录配置Linux服务器的初步流程,也就是系统安装完成后,下一步要做的事情。这主要是我自己的总结和备忘,如果有遗漏,欢迎大家补充。
下面的操作针对Debian/Ubuntu系统,其他Linux系统也类似,就是部分命令稍有不同。

第一步:root用户登录
首先,使用root用户登录远程主机(假定IP地址是128.199.209.242)。
1 | ssh root@128.199.209.242 |
这时,命令行会出现警告,表示这是一个新的地址,存在安全风险。键入yes,表示接受。然后,就应该可以顺利登入远程主机。
接着,修改root用户的密码。
1 | passwd |
第二步:新建用户
首先,添加一个用户组(这里假定为admin用户组)。
1 | addgroup admin |
然后,添加一个新用户(假定为bill)。
1 | useradd -d /home/bill -s /bin/bash -m bill |
上面命令中,参数d指定用户的主目录,参数s指定用户的shell,参数m表示如果该目录不存在,则创建该目录。
接着,设置新用户的密码。
1 | passwd bill |
将新用户(bill)添加到用户组(admin)。
1 | usermod -a -G admin bill |
接着,为新用户设定sudo权限。
1 | visudo |
visudo命令会打开sudo设置文件/etc/sudoers,找到下面这一行。
1 | root ALL=(ALL:ALL) ALL |
在这一行的下面,再添加一行。
1 | root ALL=(ALL:ALL) ALL |
上面的NOPASSWD表示,切换sudo的时候,不需要输入密码,我喜欢这样比较省事。如果出于安全考虑,也可以强制要求输入密码。
1 | root ALL=(ALL:ALL) ALL |
然后,先退出root用户的登录,再用新用户的身份登录,检查到这一步为止,是否一切正常。
1 | exit |
第三步:SSH设置
首先,确定本机有SSH公钥(一般是文件~/.ssh/id_rsa.pub),如果没有的话,使用ssh-keygen命令生成一个(可参考我写的SSH教程)。
在本机上另开一个shell窗口,将本机的公钥拷贝到服务器的authorized_keys文件。
1 | cat ~/.ssh/id_rsa.pub | ssh bill@128.199.209.242 'mkdir -p .ssh && cat - >> ~/.ssh/authorized_keys' |
然后,进入服务器,编辑SSH配置文件/etc/ssh/sshd_config。
1 | sudo cp ssh/sshd_config ~ |
在配置文件中,将SSH的默认端口22改掉,可以改成从1025到65536之间的任意一个整数(这里假定为25000)。
1 | Port 25000 |
然后,检查几个设置是否设成下面这样,确保去除前面的#号。
1 | Protocol 2 |
上面主要是禁止root用户登录,以及禁止用密码方式登录。
接着,在配置文件的末尾,指定允许登陆的用户。
1 | AllowUsers bill |
保存后,退出文件编辑。
接着,改变authorized_keys文件的权限。
1 | sudo chmod 600 ~/.ssh/authorized_keys && chmod 700 ~/.ssh/ |
然后,重启SSHD。
1 | sudo service ssh restart |
下面的一步是可选的。在本机~/.ssh文件夹下创建config文件,内容如下。
1 | Host s1 |
最后,在本机另开一个shell窗口,测试SSH能否顺利登录。
1 | ssh s1 |
第四步:运行环境配置
首先,检查服务器的区域设置。
1 | locale |
如果结果不是en_US.UTF-8,建议都设成它。
1 | sudo locale-gen en_US en_US.UTF-8 en_CA.UTF-8 |
然后,更新软件。
1 | sudo apt-get update |
最后,再根据需要,做一些安全设置,比如搭建防火墙,关闭HTTP、HTTPs、SSH以外的端口,再比如安装Fail2Ban,详细可参考这篇《Securing a Linux Server》。
(完)
reference:
A collection of editor with customized update, Rich Text Editor Plus Github
表情文件本地化
images目录下的所有表情文件夹复制到dialogs/emotion/images/文件夹下面,修改editor_config.js文件,去掉emotionLocalization项的注释,值改为true。
列表文件本地化
解压放到你的themes/文件夹下(可以按照需求放置路径),修改editor_config.js文件,修改listiconpath配置项:
1 | //如果是自己的目录,请使用 '/'开头的绝对路径 |
在发布文章的页面,引用uparse.js,并运行 uParse 函数,传入列表路径:
1 | <script type="text/javascript"> |
升级ueditor的SyntaxHighlighter,ueditor默认使用了SyntaxHighlighter的Default主题
更多配置请参见
升级UEditor的SyntaxHighlighter
更改了ueditor的默认上传位置,使用了tomcat的虚拟路径,避免重新部署后丢失先前的文件,
这里修改了com.baidu.ueditor.ConfigManager类,主要是对ueditor.config.js虚拟路径配置的处理;
还修改了com.baidu.ueditor.hunter.FileManager和com.baidu.ueditor.upload.BinaryUploader,主要是对配置了tomcat虚拟路径后的处理;
特别地,修改了原图片在线管理/文件在线附件的获取,原ueditor可以获取文件的个数并显示出来,但图片/文件显示不了,因为其封装的路径有文件,原ueditor的封装使用了绝对路径,即把
1 | D:\Tomcat 7.0.57\webapps\EditorDemo\upload\image\20150711\1436591786822080766.jpg |
这样的文件路径返回前台,这样子前台ueditor是获取不了文件的,所以改成了相对路径,见FileManager类下的getPath (File)方法;
关于tomcat虚拟路径的配置,修改tomcat conf目录下的server.xml,在Host里面添加:
1 | <Context path="/EditorDemo/ueditorupload" docBase="D:\apache\EditorDemo\ueditor\ueditorupload"/> |
这部分内容参考了
百度UEditor 上传组件 使用虚拟路径映射配置
是否保存上传文件到虚拟路径的配置请参见ueditor/jsp/下的config.json,xxxRealMappingPath指定了物理路径的位置
修改百度map组件的默认位置为广东广州
该版本基于ubuilder_1_4_3-utf8-jsp修改
ueditor这部分的最后修改时间2015年7月11日22:31:04
kindeditor/jsp文件夹下的file_manager_json.jsp和upload_json.jsp文件,用于上传文件/文件管理器的支持1 | <Context path="/EditorDemo/kindeditorupload" docBase="D:\apache\EditorDemo\kindeditor\kindeditorupload"/> |
基于ckeditor_4.5.1_full修改
添加了jsp/browse.jsp和jsp/upload.jsp两个文件,分别用于浏览服务器文件和上传图片/附件到服务器;
config.js配置了这两个文件的调用;
修改返回路径为服务器相对路径saveUrl;
修改上传文件新文件名为当前日期+随机码,tomcat需要配置虚拟路径
1 | <Context path="/EditorDemo/ckeditorupload" docBase="D:\apache\EditorDemo\ckeditor\ckeditorupload"/> |
ckeditor这部分的最后修改时间2015年7月12日12:11:55
ForkJoin是Java7提供的原生多线程并行处理框架,其基本思想是将大人物分割成小任务,最后将小任务聚合起来得到结果。
它非常类似于HADOOP提供的MapReduce框架,只是MapReduce的任务可以针对集群内的所有计算节点,可以充分利用集群的能力完成计算任务。
ForkJoin更加类似于单机版的MapReduce。
即使不通过mapreduce,仅有应用程序本身进行任务的分解与合成也是可以的,但从实现难度上考虑,自己实现可能会带来较大规模的复杂度,因此程序员急需一种范式来处理这一类的任务。
在处理多线程中已经有了如AKKA这样的基于ACTOR模型的框架,而FORKJOIN则是针对具有明显可以进行任务分割特性需求的实现。
其场景为:如果一个应用程序能够被分解成多个子任务,而且结合多个子任务的结果就能够得到最终的答案,那么它就适合使用FORK/JOIN模式来实现。
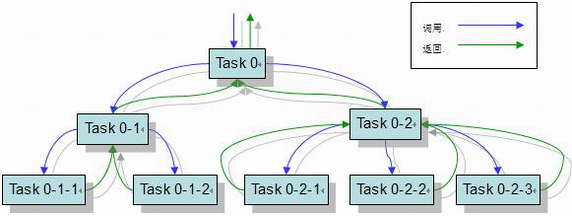
Fork/Join使用两个类完成以上两件事情:
ForkJoinTask: 我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join的操作机制,通常我们不直接继承ForkjoinTask类,只需要直接继承其子类。
ForkJoinPool:task要通过ForkJoinPool来执行,分割的子任务也会添加到当前工作线程的双端队列中,进入队列的头部。
当一个工作线程中没有任务时,会从其他工作线程的队列尾部获取一个任务。
ForkJoin框架使用了工作窃取的思想(work-stealing),算法从其他队列中窃取任务来执行,其工作流图为:
1 | package com.inspur.jiyq.forkjoin.sum; |
像这种求和以及排序的需求都可以通过FORKJOIN思想来实现,但在实际使用时还是要进行必要的性能测试来确认性能提升的幅度。
在上面这段代码中,定义了一个累加的任务,在compute方法中,判断当前值是否小于一个阈值,如果是则计算,如果不是则继续拆分,并合并子任务的中间结果。
任务定义后执行任务,Fork/Join提供一个和Executor框架的扩展线程来执行任务。
reference:
HibernateProxy异常处理
在使用Hibernate时,那么很可能遇到这样的错误:
1 | java.lang.UnsupportedOperationException: Attempted to serialize java.lang.Class: org.hibernate.proxy.HibernateProxy. Forgot to register a type adapter? |
因为gson在转换时是使用的反射机制,当获取的实体对象还在hibernate代理的时候,例如刚通过Id获取到,这时候获取到的便是代理对象HibernateProxy。
这和直接调用实体对象的get方法不同,获取对象的属性就不能起作用。
解决的方法便是将代理对象实例化,见下面的代码
1 | /** |
使用的时候将该TypeAdapter的Factory注册到GsonBuilder,上面的代码变为
1 | Gson gson = new GsonBuilder().setExcludeStrategy(ts) |
reference:
把中文文件夹改成相应的英文文件夹, 然后编辑配置文件:
1 | gedit ~/.config/user-dirs.dirs |
把文件夹指向改掉:
1 | XDG_DESKTOP_DIR="$HOME/Desktop" |
reference:
外链会产生站外请求,因此可以被利用实施 CSRF 攻击。
目前国内有大量路由器存在 CSRF 漏洞,其中相当部分用户使用默认的管理账号。通过外链图片,即可发起对路由器 DNS 配置的修改,这将成为国内互联网最大的安全隐患。
百度旅游在富文本过滤时,未考虑标签的 style 属性,导致允许用户自定义的 CSS。因此可以插入站外资源: 第1张")
所有浏览该页面的用户,都能发起任意 URL 的请求: 第2张")
由于站外服务器完全不受控制,攻击者可以控制返回内容:
1 | http://admin:admin@192.168.1.1/userRpm/PPPoECfgAdvRpm.htm?wan=0&lcpMru=1480&ServiceName=&AcName=&EchoReq=0&manual=2&dnsserver=黑客服务器&dnsserver2=4.4.4.4&downBandwidth=0&upBandwidth=0&Save=%B1%A3+%B4%E6&Advanced=Advanced |
 第3张")
演示中,随机测试了几个帖子,在两天时间里收到图片请求 500 多次,已有近 10 个不同的 IP 开始向我们发起 DNS 查询。 第4张")
通过中间人代理,用户的所有隐私都能被捕捉到。还有更严重的后果,查考流量劫持危害探讨
要是在热帖里『火前留名』,那么数量远不止这些。
如果使用发帖脚本批量回复,将有数以万计的用户网络被劫持。
杜绝用户的一切外链资源。需要站外图片,可以抓回后保存在站内服务器里。
对于富文本内容,使用白名单策略,只允许特定的 CSS 属性。
尽可能开启 Content Security Policy 配置,让浏览器底层来实现站外资源的拦截。
富文本是 XSS 的重灾区。
富文本的实质是一段 HTML 字符。由于历史原因,HTML 兼容众多不规范的用法,导致过滤起来较复杂。几乎所有使用富文本的产品,都曾出现过 XSS 注入。
旅游发帖支持富文本,我们继续刚才的演示。 第5张")
由于之前已修复过几次,目前只能注入 embed 标签和 src 属性。
但即使这样,仍然可以嵌入一个框架页面: 第6张")
因为是非同源执行的 XSS,所以无法获取主页面的信息。但是可以修改 top.location,将页面跳转到第三方站点。
将原页面嵌入到全屏的 iframe 里,伪造出相同的界面。然后通过浮层登录框,进行钓鱼。 第7张")
总之,富文本中出现可执行的元素,页面安全性就大打折扣了。
这里不考虑后端的过滤方法,讲解使用前端预防方案:
无论攻击者使用各种取巧的手段,绕过后端过滤,但这些 HTML 字符最终都要在前端构造成元素,并渲染出来。
因此可以在 DOM 构造之后、渲染之前,对离屏的元素进行风险扫描。将可执行的元素(script,iframe,frame,object,embed,applet)从缓存中移除。
或者给存在风险的元素,加上沙箱隔离属性。
DOM 仅仅被构造是不会执行的,只有添加到主节点被渲染时才会执行。所以这个过程中间,可以实施安全扫描。
实现细节可以参考:http://www.etherdream.com/FunnyScript/richtextsaferender.html
如果富文本是直接输入到静态页面里的,可以考虑使用 MutationEvent 进行防御。详细参考:http://fex.baidu.com/blog/2014/06/xss-frontend-firewall-2/
但推荐使用动态方式进行渲染,可扩展性更强,并且性能消耗最小。
浏览器提供了一个 opener 属性,供弹出的窗口访问来源页。但该规范设计的并不合理,导致通过超链接打开的页面,也能使用 opener。
因此,用户点了网站里的超链接,导致原页面被打开的第三方页面控制。
虽然两者受到同源策略的限制,第三方无法访问原页面内容,但可以跳转原页面。
由于用户的焦点在新打开的页面上,所以原页面被悄悄跳转,用户难以觉察到。当用户切回原页面时,其实已经在另一个钓鱼网站上了。
百度贴吧目前使用的超链接,就是在新窗口中弹出,因此同样存在该缺陷。
攻击者发一个吸引用户的帖子。当用户进来时,引诱他们点击超链接。
通常故意放少部分的图片,或者是不会动的动画,先让用户预览一下。要是用户想看完整的,就得点下面的超链接: 第8张")
由于扩展名是 gif 等图片格式,大多用户就毫无顾虑的点了。
事实上,真正的类型是由服务器返回的 MIME 决定的。所以这个站外资源完全有可能是一个网页: 第9张")
当用户停留在新页面里看动画时,隐匿其中的脚本已悄悄跳转原页面了。
用户切回原页面时,其实已在一个钓鱼网站上: 第10张")
在此之上,加些浮层登录框等特效,很有可能钓到用户的一些账号信息。
该缺陷是因为 opener 这个属性引起的,所以得屏蔽掉新页面的这个属性。
但通过超链接打开的网页,无法被脚本访问到。只有通过 window.open 弹出的窗口,才能获得其对象。
所以,对页面中的用户发布的超链接,监听其点击事件,阻止默认的弹窗行为,而是用 window.open 代替,并将返回窗体的 opener 设置为 null,即可避免第三方页面篡改了。
详细实现参考:http://www.etherdream.com/FunnyScript/opener_protect.html
当然,实现中无需上述 Demo 那样复杂。根据实际产品线,只要监听用户区域的超链接就可以。
支持自定义装扮的场合,往往是钓鱼的高发区。
一些别有用心者,利用装扮来模仿系统界面,引诱用户上钩。
百度空间允许用户撰写自定格式的内容。
其本质是一个富文本编辑器,这里不演示 XSS 漏洞,而是利用样式装扮,伪装一个钓鱼界面。
百度空间富文本过滤元素、部分属性及 CSS 样式,但未对 class 属性启用白名单,因此可以将页面上所有的 CSS 类样式,应用到自己的内容上来。 第11张")
规定用户内容尺寸限制,可以在提交时由用户自己确定。
不应该为用户的内容分配无限的尺寸空间,以免恶意用户设置超大字体,破坏整个页面的浏览。
最好将用户自定义的内容嵌套在 iframe 里,以免影响到页面其他部位。
如果必须在同页面,应将用户内容所在的容器,设置超过部分不可见。以免因不可预测的 BUG,导致用户能将内容越界到产品界面上。
自定义装扮通常支持站外超链接。
相比贴吧这类简单纯文字,富文本可以将超链接设置在其他元素上,例如图片。
因此这类链接非常具有迷惑性,用户不经意间就点击到。很容易触发之前提到的修改 opener 钓鱼。 第12张")
如果在图片内容上进行伪装,更容易让用户触发一些危险操作。 第13张")
要是和之前的区域越界配合使用,迷惑性则更强: 第14张")
 第15张")
和之前一样,对于用户提供的超链接,在点击时进行扫描。如果是站外地址,则通过后台跳转进入,以便后端对 URL 进行安全性扫描。
如果服务器检测到是一个恶意网站,或者目标资源是可执行文件,应给予用户强烈的警告,告知其风险。
点击劫持算是比较老的攻击方式了,基本原理大家也都听说过。就是在用户不知情的前提下,点击隐藏框架页面里的按钮,触发一些重要操作。
但目前在点击劫持上做防御的并不多,包括百度绝大多数产品线目前都未考虑。
能直接通过点击完成的操作,比较有意义的就是关注某用户。例如百度贴吧加关注的按钮: 第16张")
攻击者事先算出目标按钮的尺寸和坐标,将页面嵌套在自己框架里,并设置框架的偏移,最终只显示按钮: 第17张")
接着通过 CSS 样式,将目标按钮放大,占据整个页面空间,并设置全透明。 第18张")
这时虽看不到按钮,但点击页面任意位置,都能触发框架页中加关注按钮的点击: 第19张")
事实上,点击劫持是很好防御的。
因为自身页面被嵌套在第三方页面里,只需判断 self == top 即可获知是否被嵌套。
对一些重要的操作,例如加关注、删帖等,应先验证是否被嵌套。如果处于第三方页面的框架里,应弹出确认框提醒用户。
确认框的坐标位置最好有一定的随机偏移,从而使攻击者构造的点击区域失效。
先来说说隐身模式的启用方法吧
1.键盘快捷:Ctrl + Shift + N。
2.在Windows7下的任务栏处,右击“Chrome”图标,会出一个下拉菜单,点击“新建隐身窗口”。

3.你还可以在一个正在浏览的页面中,通过“右键点击链接”出现下拉菜单,选择“在隐身窗口中打开链接”,直接进入隐身窗口(如下图)。

简单一点的说,Chrome的隐身模式的好处就是保持你的隐私。具体表现在在此窗口中查看的网页不会显示在浏览器历史记录或搜索历史记录中,关闭隐身窗口后也不会在计算机上留下 Cookie 之类的其他痕迹,但会保留所有下载的文件或创建的书签,一般什么情境下你会使用Chrome的隐身模式呢
1、在注册网上银行等业务方面的网站时
2、你用朋友的电脑上网,而又不想在“历史记录”中被他发现你上了哪些网站
Chrome最强大的地方莫过于有各种各样的插件了,那如何在隐身模式下启用或禁用插件呢?点击右上角“扳手“–》”更多工具“–》”扩展程序”,在这个页面中,你可以选择哪些插件可以用于Chrome的隐身模式

事实上隐身模式并非是万能的,Chrome给出的建议是在以下一些情况下谨防失效:
| 热键组合 | 实现的功能 |
|---|---|
| F1 | Google浏览器帮助中心 |
| F12 | 打开[Chrome控制台](http://www.codeceo.com/article/chrome-console.html "Chrome控制台") |
| Ctrl+J | 进入“下载内容”页面 |
| Ctrl+H | 查看“历史记录”页面 |
| Ctrl+D | 将此页加入书签 |
| Ctrl+F | 打开/关闭 搜索框(搜索页面内的文字) |
| Ctrl+P | 打开打印窗口 |
| Ctrl+T | 新建标签页 |
| Ctrl+W | 关闭标签页 |
| Ctrl++ | 放大页面 |
| Ctrl+- | 缩小页面 |
| Ctrl+0 | 默认页面字体大小 |
| Ctrl+Shift+T | 重新打开最近关闭的一个标签 |
| Ctrl+N | 新建一个窗口 |
| Ctrl+Shift+N | 新建一个隐身模式窗口 |
| Ctrl+Tab | 从左到右,标签循环浏览 |
| Ctrl+Shift+Tab | 从右到左,标签循环浏览 |
| Ctrl+1-8 | 分别指向第1、2、3…8标签 |
| Ctrl+9 | 跳转到最后一个标签 |
| Ctrl+Shift+Del | 打开“清除浏览数据”窗口 |
| Ctrl+Shift+B | 显示/隐藏书签栏 |
| Shift+Esc | 开打Chrome任务管理器 |
| Alt+Home | 在当前标签打开首页 |
| Alt+D/Ctrl+L | 迅速突出地址栏 |
| Ctrl+Enter | 在地址栏自动添加www或.com |
| Ctrl+Shift+V | 粘帖剪切板中的纯文本格式 |
| Shift+Alt+T | 将焦点聚集到工具栏中的第一个工具 |
| Tab (after Shift+Alt+T) | 工具栏中将焦点移到各个选项上 |
| Space or Enter (after Shift+Alt+T) | 可激活工具栏按钮 |
| Shift+F10 (after Shift+Alt+T) | 可打开相关右键菜单 |
| Esc (after Shift+Alt+T) | 可将焦点从工具栏移回到网页上 |
估计很多人不知道Chrome地址栏功能,作为一个Chrome用户,必须懂的。以下我要介绍的这些指令在Chrome地址栏输入即可
about:version – 显示当前版本 也可以是chrome-resource://about/
about:plugins – 显示已安装插件
about:histograms – 显示历史记录
chrome://history2 – 浏览历史 History2
about:dns – 显示DNS状态
about:cache, 重定向到 view-cache: 显示缓存页面
view-cache:stats – 缓存状态
about:stats – 显示状态
chrome-resource://new-tab/ – 新标签页
about:memory – 可以查看内存和进程占用。也可以Shift+ESC,点击Statistics for nerds(傻瓜统计信息)
about:flags – Chrome高级设置
也许大家看到上面 这一大片的指令,估计都没有动手去试试的欲望了。
事实上你根本就无需记这些指令,你只需要记住一个万能的就行,那就是chrome://about/
你在Chrome地址栏输入这个,就会出现如下截图,哈哈,万能吧!(还有好多,我只截了一部分哦)

下面我就针对一些重要的指令一一介绍一下!(别嫌麻烦哦,真心挺有用的)
用于查看浏览器当前访问的标签,打开全局访问模式可以查看:各个标签页面的文档系统树,大家看到的效果图如下所示:

这个我就不细说了,只有你浏览HTML5网站时才会有显示缓存记录,这时用这个命令就可以对HTML5应用的离线存储进行管理
使用这个命令就可以快速打开Chrome网上应用商店
相信大家平常少不了用书签来记录一些自己认为特别好的网站以便后时之需。哈哈,这时这条命令就派上用场了。
哎,对于这个指令,我只能说看看而已吧,别太认真了。因为它只能用于查看,却不能进行其它操作。
不过,虽然是查看,却可以带来异样的感觉。比如说点击某个缓存的图片文件它会用16进制的方法显示缓存文件

想自动升级Chrome的用它吧,不过不知道为什么有两条指令。(不过也许这就是条条大道通罗马吧 哈哈 扯远了)
显示所有 chrome 的相关功能的连接
如果你相看看相关组件是否需要升级,可以使用它哦。

这个功能不太懂是….也许是为了调试用的吧

如果启用的话将使用情况统计信息和崩溃报告自动发送给 Google

除此之外还可以查看某个软件的主页(源码),点击下图所示的show license试试

查看设备,比如链接的打印机
DNS记录查看,如果有网络故障记得先来找他,chrome 还会定时更新hosts的DNS

查看下载文件的记录。这个命令太有用了。也是我最最经常使用的。
这个没啥好说的,大家都知道Chrome最强大的地方就在于有各种各校的插件和各式各样的扩展程序。那这些扩展程序主要是干嘛呢,无非就是由某些大神开发用于提高咱们的工作效率的
这个更没啥好说的,没专业技能不要修改默认设置,比如 GPU的某些设置。


Google Cloud Messaging for Android 是谷歌新推出的云推送消息服务,简称 GCM。该服务可帮助你将数据从服务端发送至应用
查看访问的历史记录
列出使用你本地存储的 html5站点,然后你可以“强制清除”它,或者“下载”它

这个对于开发人员来说应该最体贴的功能啦,包括设备、检查页面 、扩展、App、共享、服务等选项卡。上图就知道了

失效的调试信息,可以查看调试日志以及内部详细信息。这个我还真没摸出它的价值来,有知道的可以告诉我一下。
用来调试在线播放的一些数据,比如测试 音频流
查看 chrome 各个 网页标签、插件 消耗的内存

每个页面、插件详细的内存信息;点击 Update 可以获取json格式的进程,以及可视化的信息:PID、Name(Browser/GPU/TAB/History)、Memory……

本地客户端 Native Client 环境信息,包括浏览器、操作系统、插件等


我只能说这个大强大了,太实用了。你用用就知道它的厉害了

结合 omnibox 一起使用看看的智能程序。


包括,基础信息、上一次更新、登陆令牌、账户

我不得不说一下,这个确实好玩。(还是忍不住暴露了一下女生天生爱玩的特质)

这个对开发人员来说太实用了。上图就知道啦

监听用户行为,比如你的鼠标点击事件,访问url事件都会被记录下来。哈哈,你看,连我切换浏览器都被捕获到了。是不是挺强大的。

作为一名后台开发人员(虽然现在因为个人兴趣转前端了),Chrome就是我心里的神。不是我在IE背后说它的坏话,相对IE来说,Chrome真的是不管是对普通用户还是对开发人员都是非常人性化的。
我在另外一个博客上有写两篇关于Chrome控制台的相关文章,大家有兴趣也可以了解一下。所谓工欲善其事必先利其器,掌握好工具对于后续工作来说效率还是…..
Chrome 控制台console的用法(学了之后对于调试js可是大大有用的哦)
接下来我会写一篇关于Chrome控制台各个面板的使用,希望大家有空多多关注。文章写的不好的地方还请多多包涵。
reference: